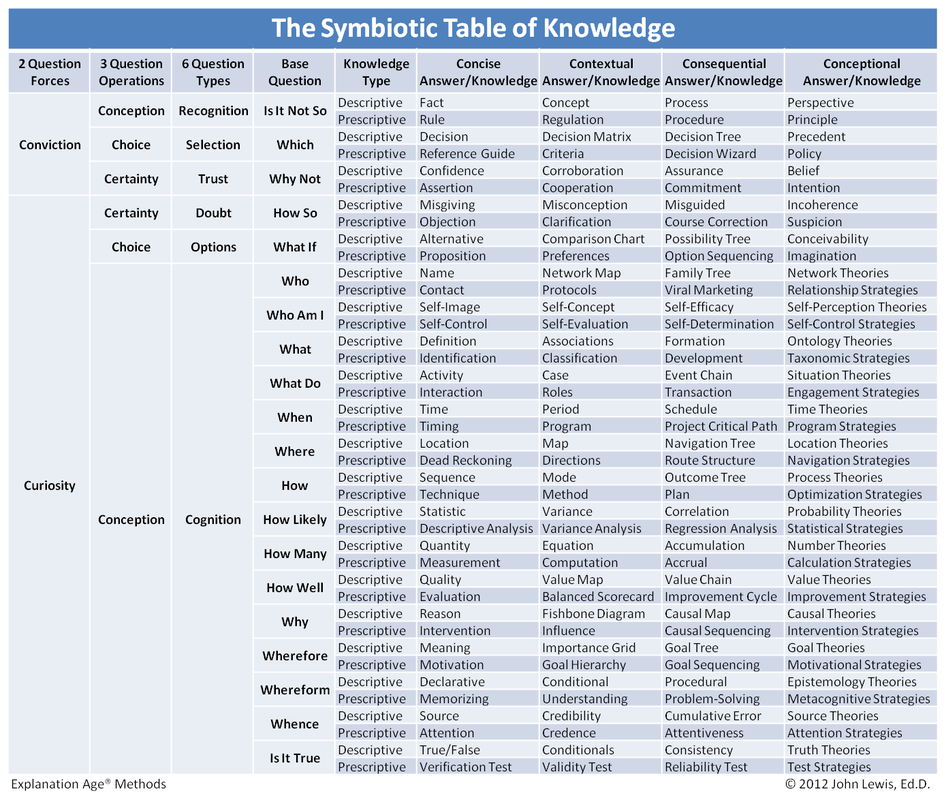
The Symbiotic Table of Knowledge™What are the fundamental types of questions that humans ask?
What are the fundamental types of answers that humans expect? Can we produce a table from these fundamental questions and answers? YES! The Symbiotic Table of Knowledge: The ability to know, to have access to knowledge, is now measured not by IQ tests but by the network speed of your smart phone. Simply having knowledge is no longer the primary advantage. The primary advantage comes from asking the right question. This means that Knowledge is no longer the ultimate power. Questioning is power. Remember, Einstein said “Imagination is more important than knowledge.” Questioning Skills create the answers we call “knowledge.” What we know is intricately related to what we ask, and what we can ask. So study the questions first. Questions come from two forces: curiosity and conviction. For example, a question during an investigation of a suspect will either be “Where were you last night?” or “Isn’t it true that you were out last night?” Even the social forums we find ourselves within are based on whether our questions are coming from curiosity or from conviction. For example, the forum is called dialogue when the participants are asking questions from curiosity. But the forum is called groupthink when the participants are asking collaborative questions from conviction, and called debate when the participants are asking competitive questions from conviction. Questions come from three operations: conception, choice, and certainty. If I asked you to list all the things that you can do to a database record, you might say that you could add a name, add an address, update a phone number, etc. But there are really only a few basic operations that you can perform on a database record: create, update, read, and delete. Similarly, if I asked you to list all of the types of questions, you might provide a list like: who, what, where, when, why, how, which, etc. But these questions are not the innate question operations. The three most basic question operations are conception, choice, and certainty. Imagine a table or spreadsheet as a framework, with all of the cells filled in, except one. That empty cell creates a question of conception to fill this void. For example, “What goes in this box?” Then imagine the answer to that question of conception coming back with several options. Now this creates a question of choice to narrow it down. For example, “Which is the right one?” Finally, for each completed cell, this will create a question of certainty to see how sure we are of having the right answer. For example, “Are you sure this is right?” Given this framework-question theory, which says that questions are derived from frameworks in three ways, and given that we ask these questions from curiosity or conviction, we find there are six (2x3) foundational question types. Applying The Table of Knowledge
Education: Imagine the symbiotic table of knowledge being used as a balanced scorecard to determine if an education consisted of memorizing for conviction, or if the education also provided an ability to understand from curiosity. And not just for concise knowledge, but also for contextual, consequential, and conceptional knowledge. (In the table below, find the terms: Concise and Contextual)
Unlearning: Imagine being able to support the unlearning process by first identifying specific knowledge held in conviction, and then being able to point to the matching specific knowledge that would need to be held in curiosity as well. Making people aware of the types of questions they are asking from conviction, and moving them into asking questions from curiosity, is the first step in unlearning. (In the table below, find the terms: Curiosity and Conviction) Situational Awareness: Imagine being asked to provide, for each knowledge-type listed in the symbiotic table of knowledge, an example related to your situation. What you may find is that most people cannot complete the table, especially the cell that requires them to recognize their unique perspective. You will probably also find that most awareness is concise – not contextual, consequential, or conceptional. And most awareness is either descriptive or prescriptive – without a balance between the two. (In the table below, find the terms: Descriptive, Prescriptive, and Perspective) Conflict Resolution: Imagine distinguishing between a fact and a proven fact. A fact is just concise knowledge we hold with conviction. The term “fact-checking” exists because a fact does not necessarily mean something is true - just that it is held as true. A proven fact, which has nothing to do with polls or corroboration, is based on our curiosity in truth-seeking. (In the table below, find the terms: Fact, Corroboration, and True) Knowledge Management: Imagine the symbiotic table of knowledge being used as a checklist to see if current processes, systems, and data mining techniques are providing us with all of the knowledge associated with a given domain. (In the table below, find the terms: Rule, Policy, Correlation, and Associations) Motivational: Imagine distinguishing between the questions why and wherefore. In William Shakespeare’s classic story of Romeo and Juliet, when Juliet asked “Wherefore art thou, Romeo?” she was not asking for where he might be. She was asking for the meaning of him, and the “why of why” that he must “exist.” Over time, we have dropped the use of the term “wherefore,” seeing it as simply redundant with the term “why.” But it is a different question from “why,” and so it produces a different type of knowledge. (In the table below, find the terms: Why, Wherefore, Whereform, and Whence) |
From the Book
"We are all familiar with the term know-how, and it seems reasonable to conclude that this is a type of knowledge that was gained by asking the question “how?” This relationship between the basic types of knowledge and the basic types of questions can be found in the symbiotic table of knowledge.
From a philosophy background, Descartes defined knowledge in terms of doubt. But Peirce said “We cannot begin with complete doubt. We must begin with all the prejudices which we actually have when we enter upon the study of philosophy.” So, if we recognize doubt as one of the six foundational question types, we can create the question side of the framework-question theory table. From an education background, Merrill classified the content from learning (knowledge) within his component display theory as facts, concepts, procedures, and principles. So, we can generalize these as answers which are concise, contextual, consequential, and conceptional. Finally, Gentner and Stevens described mental models as having the ability to infer between prescriptive and descriptive knowledge. Combining these views of knowledge led to “The Symbiotic Table of Knowledge” which presents knowledge as answers to questions, but within an inference framework that also generates new questions." |